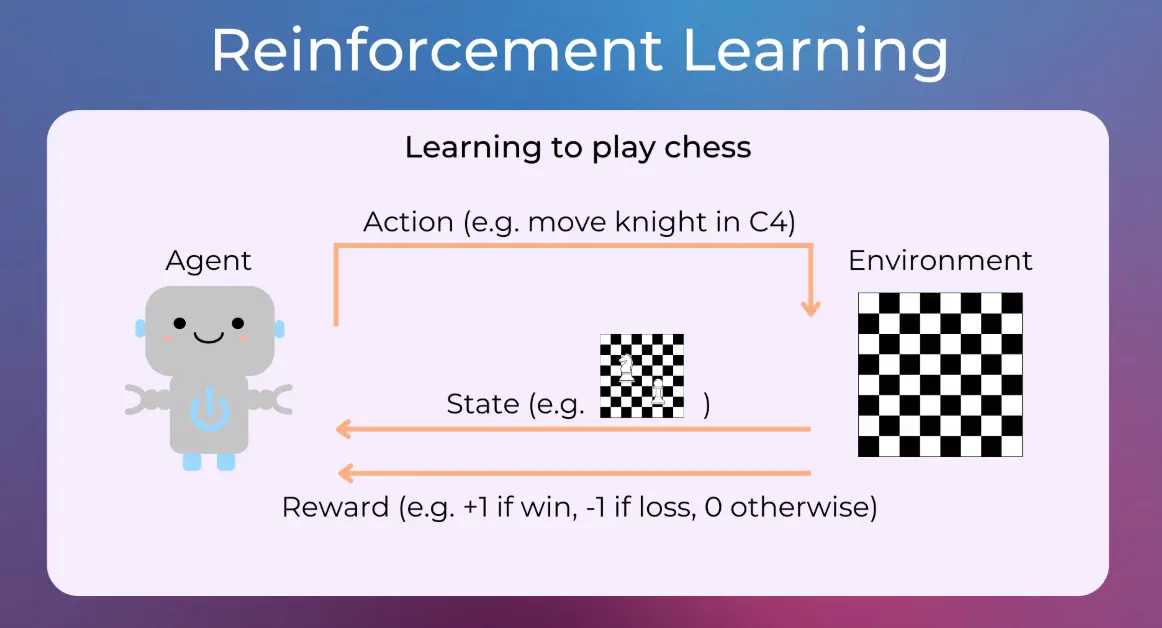
Reinforcement learning (RL) is a branch of machine learning where an agent learns to make decisions by interacting with an environment to maximize cumulative rewards. Unlike supervised learning, RL relies on trial and error, receiving feedback in the form of rewards or penalties for its actions.
Key elements include:
Agent: The entity that takes actions and learns from experiences.
Environment: The external system the agent interacts with, which responds to actions.
States: Representations of the environment at any given time, used to inform decisions.
Actions: The choices available to the agent in each state.
Rewards: Scalar values that indicate the immediate benefit or cost of an action, guiding the learning process.
RL operates through mechanisms like:
Policies: Strategies that map states to actions, determining how the agent behaves.
Value functions: Estimates of the long-term reward for being in a particular state or taking an action, helping evaluate decisions.
Exploration and exploitation: Balancing the need to try new actions (exploration) with leveraging known successful ones (exploitation).
Common algorithms include Q-learning, which uses a table to estimate action values, and deep RL methods like Deep Q-Networks (DQN), which combine RL with neural networks for complex environments.
Applications span various fields, such as:
– Robotics for task automation.
– Game AI, as seen in AlphaGo.
– Autonomous systems like self-driving cars.
– Resource management in finance and healthcare.
RL’s strength lies in handling sequential decision-making problems, but it faces challenges like high sample inefficiency and the risk of unstable learning. Ongoing research focuses on improving efficiency and safety.
Table of contents
- Part 1: OnlineExamMaker AI quiz maker – Make a free quiz in minutes
- Part 2: 20 reinforcement learning quiz questions & answers
- Part 3: AI Question Generator – Automatically create questions for your next assessment
Part 1: OnlineExamMaker AI quiz maker – Make a free quiz in minutes
What’s the best way to create a reinforcement learning quiz online? OnlineExamMaker is the best AI quiz making software for you. No coding, and no design skills required. If you don’t have the time to create your online quiz from scratch, you are able to use OnlineExamMaker AI Question Generator to create question automatically, then add them into your online assessment. What is more, the platform leverages AI proctoring and AI grading features to streamline the process while ensuring exam integrity.
Key features of OnlineExamMaker:
● Create up to 10 question types, including multiple-choice, true/false, fill-in-the-blank, matching, short answer, and essay questions.
● Build and store questions in a centralized portal, tagged by categories and keywords for easy reuse and organization.
● Automatically scores multiple-choice, true/false, and even open-ended/audio responses using AI, reducing manual work.
● Create certificates with personalized company logo, certificate title, description, date, candidate’s name, marks and signature.
Automatically generate questions using AI
Part 2: 20 reinforcement learning quiz questions & answers
or
1. Question: What is reinforcement learning?
Options:
A. A type of supervised learning where models learn from labeled data.
B. A method where an agent learns to make decisions by interacting with an environment to maximize cumulative reward.
C. A technique for clustering unlabeled data.
D. A process of reducing model complexity to avoid overfitting.
Answer: B
Explanation: Reinforcement learning involves an agent taking actions in an environment to receive rewards, learning optimal policies through trial and error to maximize long-term rewards.
2. Question: In a Markov Decision Process (MDP), what does the transition model represent?
Options:
A. The immediate reward for an action in a state.
B. The probability of moving from one state to another given an action.
C. The policy that the agent follows.
D. The value function of states.
Answer: B
Explanation: The transition model in an MDP defines the probabilities of transitioning to next states based on the current state and action, ensuring the process is memoryless.
3. Question: What is the role of the discount factor in reinforcement learning?
Options:
A. It determines the learning rate of the algorithm.
B. It weights future rewards to make them less valuable than immediate ones, preventing infinite horizons.
C. It controls the exploration rate in epsilon-greedy methods.
D. It defines the number of episodes in training.
Answer: B
Explanation: The discount factor (γ) reduces the impact of future rewards, encouraging the agent to prioritize short-term gains and ensuring convergence in value calculations.
4. Question: In Q-Learning, what does the Q-value represent?
Options:
A. The expected cumulative reward of taking an action in a state and following the optimal policy thereafter.
B. The probability of transitioning between states.
C. The immediate reward for an action.
D. The policy gradient update.
Answer: A
Explanation: Q-values estimate the total future reward from a state-action pair, allowing the agent to learn an optimal policy through updates based on observed rewards.
5. Question: What is exploration in reinforcement learning?
Options:
A. The process of exploiting known high-reward actions.
B. Trying out different actions to discover potentially better rewards, even if they are uncertain.
C. Evaluating the value function at the end of training.
D. Updating the policy based on gradients.
Answer: B
Explanation: Exploration helps the agent avoid local optima by sampling various actions, balancing with exploitation to improve overall learning efficiency.
6. Question: Which algorithm is an example of model-free reinforcement learning?
Options:
A. Dynamic Programming.
B. Q-Learning.
C. Value Iteration.
D. Policy Iteration.
Answer: B
Explanation: Q-Learning is model-free as it does not require knowledge of the environment’s transition model; it learns directly from experiences.
7. Question: What is a policy in reinforcement learning?
Options:
A. A mapping from states to actions that the agent uses to make decisions.
B. The total reward accumulated over an episode.
C. The learning rate of the algorithm.
D. The state space of the environment.
Answer: A
Explanation: A policy defines the agent’s strategy for selecting actions based on the current state, which can be deterministic or stochastic.
8. Question: In Deep Q-Networks (DQN), what is the purpose of the experience replay buffer?
Options:
A. To store and randomly sample past experiences for training, reducing correlations between samples.
B. To compute the discount factor.
C. To define the action space.
D. To visualize the agent’s policy.
Answer: A
Explanation: Experience replay breaks the temporal correlations in sequential data, stabilizing the training of neural networks in DQN.
9. Question: What does the Bellman equation describe?
Options:
A. The optimal value function for a state in an MDP.
B. The relationship between the value of a state and the values of its successor states.
C. The gradient of the policy.
D. The exploration strategy.
Answer: B
Explanation: The Bellman equation expresses the value of a state as the immediate reward plus the discounted value of the next state, forming the basis for value iteration.
10. Question: Why is the epsilon-greedy strategy used in Q-Learning?
Options:
A. To always select the action with the highest Q-value.
B. To balance exploration and exploitation by randomly selecting actions with probability epsilon.
C. To increase the learning rate over time.
D. To compute the reward function.
Answer: B
Explanation: Epsilon-greedy ensures the agent explores the environment by choosing random actions some of the time, preventing it from getting stuck in sub-optimal policies.
11. Question: What is the difference between on-policy and off-policy learning?
Options:
A. On-policy learns from actions taken by the current policy, while off-policy learns from actions of a different policy.
B. On-policy uses a model of the environment, while off-policy does not.
C. On-policy is only for continuous spaces, and off-policy is for discrete.
D. There is no difference; they are the same.
Answer: A
Explanation: On-policy methods, like SARSA, evaluate or improve the policy that is used to make decisions, whereas off-policy methods, like Q-Learning, can learn from data generated by another policy.
12. Question: In Actor-Critic methods, what is the role of the critic?
Options:
A. To directly output actions.
B. To evaluate the actor’s policy by estimating value functions.
C. To handle exploration only.
D. To define the state space.
Answer: B
Explanation: The critic provides feedback on the actor’s actions by approximating the value function, guiding the policy improvements.
13. Question: What is the reward hypothesis in reinforcement learning?
Options:
A. All goals can be described as the maximization of expected cumulative reward.
B. Rewards are always positive.
C. The agent must receive rewards in every state.
D. Rewards decrease over time.
Answer: A
Explanation: The reward hypothesis posits that any intelligent behavior can be framed as maximizing some form of reward, serving as the foundation for RL goal-setting.
14. Question: Which of the following is a disadvantage of Monte Carlo methods in RL?
Options:
A. They require a model of the environment.
B. They have high variance and need full episodes to update estimates.
C. They are faster than temporal difference methods.
D. They work well in continuous state spaces.
Answer: B
Explanation: Monte Carlo methods estimate values from complete episodes, leading to high variance and inefficiency in long or infinite horizon problems.
15. Question: What is temporal difference learning?
Options:
A. A method that updates estimates based on other estimates, without waiting for a complete episode.
B. A technique for policy gradient ascent.
C. A way to model the environment dynamics.
D. An exploration strategy.
Answer: A
Explanation: Temporal difference learning, like in Q-Learning, combines ideas of Monte Carlo and dynamic programming, updating values incrementally as new information arrives.
16. Question: In policy gradient methods, what is the objective?
Options:
A. To directly optimize the policy parameters to maximize expected reward.
B. To estimate Q-values only.
C. To minimize the state space.
D. To use a fixed policy.
Answer: A
Explanation: Policy gradient methods adjust the policy’s parameters using gradients of the expected reward, allowing for learning in continuous action spaces.
17. Question: What is the curse of dimensionality in reinforcement learning?
Options:
A. The exponential increase in state space size with more dimensions, making learning inefficient.
B. A problem where rewards are negative.
C. An issue with discount factors less than 1.
D. The need for more episodes in training.
Answer: A
Explanation: High-dimensional state spaces lead to sparse data and computational challenges, often requiring techniques like function approximation to mitigate.
18. Question: How does SARSA differ from Q-Learning?
Options:
A. SARSA is on-policy, using the next action from the current policy, while Q-Learning is off-policy.
B. SARSA requires a model, while Q-Learning does not.
C. They are identical algorithms.
D. SARSA uses Monte Carlo methods only.
Answer: A
Explanation: SARSA updates based on the action the agent actually takes next, making it on-policy, whereas Q-Learning assumes the optimal action, making it off-policy.
19. Question: What is function approximation in RL?
Options:
A. Using a function, like a neural network, to approximate value functions or policies in large state spaces.
B. Exactly computing values without any error.
C. A method for discounting rewards.
D. A way to define actions.
Answer: A
Explanation: Function approximation generalizes from limited samples in high-dimensional spaces, enabling RL in complex environments like those in Deep RL.
20. Question: In multi-armed bandit problems, what is the goal?
Options:
A. To maximize cumulative reward over multiple pulls of arms with unknown reward distributions.
B. To minimize the state space.
C. To use supervised learning for predictions.
D. To explore all arms equally.
Answer: A
Explanation: Multi-armed bandits focus on balancing exploration and exploitation to achieve the highest total reward, serving as a simplified RL problem.
or
Part 3: AI Question Generator – Automatically create questions for your next assessment
Automatically generate questions using AI