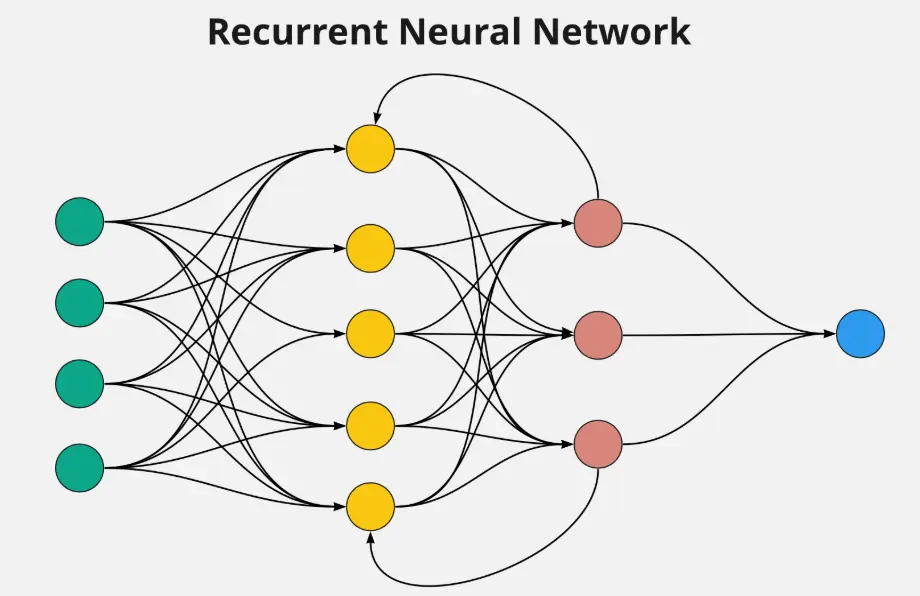
Recurrent Neural Networks (RNNs) are a type of artificial neural network designed to handle sequential data, such as time series, speech, or text. Unlike traditional feedforward networks, RNNs feature loops that allow information to persist across steps, enabling them to maintain a form of memory. This architecture makes RNNs ideal for tasks involving patterns over time, like language modeling, speech recognition, and predictive analytics. However, they can struggle with long-term dependencies due to issues like vanishing gradients, leading to advancements such as LSTM and GRU variants.
Table of contents
- Part 1: OnlineExamMaker AI quiz generator – The easiest way to make quizzes online
- Part 2: 20 recurrent neural networks (RNNs) quiz questions & answers
- Part 3: Save time and energy: generate quiz questions with AI technology
Part 1: OnlineExamMaker AI quiz generator – The easiest way to make quizzes online
Are you looking for an online assessment to test the recurrent neural networks (RNNs) knowledge of your learners? OnlineExamMaker uses artificial intelligence to help quiz organizers to create, manage, and analyze exams or tests automatically. Apart from AI features, OnlineExamMaker advanced security features such as full-screen lockdown browser, online webcam proctoring, and face ID recognition.
Take a product tour of OnlineExamMaker:
● Includes a safe exam browser (lockdown mode), webcam and screen recording, live monitoring, and chat oversight to prevent cheating.
● AI Exam Grader for efficiently grading quizzes and assignments, offering inline comments, automatic scoring, and “fudge points” for manual adjustments.
● Embed quizzes on websites, blogs, or share via email, social media (Facebook, Twitter), or direct links.
● Handles large-scale testing (thousands of exams/semester) without internet dependency, backed by cloud infrastructure.
Automatically generate questions using AI
Part 2: 20 recurrent neural networks (RNNs) quiz questions & answers
or
Question 1:
What is the primary purpose of Recurrent Neural Networks (RNNs)?
A. To process data with spatial hierarchies, like images
B. To handle sequential data by maintaining a hidden state
C. To perform unsupervised learning on clustered data
D. To optimize feature extraction in convolutional layers
Answer: B
Explanation: RNNs are designed to work with sequential data, such as time series or natural language, by using loops to allow information to persist, enabling the network to maintain a ‘memory’ of previous inputs.
Question 2:
In RNNs, what does the term “hidden state” refer to?
A. The output layer’s final predictions
B. The input data fed into the network
C. A vector that captures information from previous time steps
D. The weights of the connections between neurons
Answer: C
Explanation: The hidden state in RNNs acts as a memory that stores information from prior inputs, allowing the network to make decisions based on the sequence’s context.
Question 3:
Why do vanilla RNNs suffer from vanishing gradients?
A. Because gradients grow exponentially during backpropagation
B. Due to the use of activation functions that amplify errors
C. As a result of multiplying gradients over many time steps, causing them to diminish
D. From over-regularization techniques applied to the model
Answer: C
Explanation: In vanilla RNNs, gradients are calculated through backpropagation through time, and repeated multiplication can make them very small, hindering the learning of long-term dependencies.
Question 4:
What type of activation function is commonly used in the hidden layers of RNNs?
A. ReLU
B. Sigmoid
C. Tanh
D. Softmax
Answer: C
Explanation: Tanh is often used in RNN hidden layers because it outputs values between -1 and 1, which helps in maintaining the flow of gradients and capturing both positive and negative dependencies.
Question 5:
How does an RNN process a sequence of data?
A. By processing the entire sequence at once in a feedforward manner
B. Through parallel processing of independent data points
C. By looping back the output to the input for each time step
D. By converting the sequence into a static image representation
Answer: C
Explanation: RNNs process sequences step by step, where the output from one time step is fed back into the network as input for the next, allowing it to handle variable-length sequences.
Question 6:
What is a key advantage of Long Short-Term Memory (LSTM) networks over vanilla RNNs?
A. LSTMs require less computational power
B. LSTMs can handle longer dependencies without vanishing gradients
C. LSTMs do not use hidden states
D. LSTMs are designed only for image data
Answer: B
Explanation: LSTMs use gates (input, forget, and output) to control the flow of information, effectively mitigating the vanishing gradient problem and capturing long-term dependencies.
Question 7:
In an LSTM cell, what is the role of the forget gate?
A. To decide what new information to add to the cell state
B. To output the final hidden state
C. To remove or keep information from the cell state
D. To process the input data directly
Answer: C
Explanation: The forget gate uses a sigmoid function to determine which parts of the previous cell state to discard, helping the network forget irrelevant information over time.
Question 8:
What is Gated Recurrent Unit (GRU)?
A. A simplified version of LSTM with fewer gates
B. A type of feedforward neural network
C. An RNN variant that only processes images
D. A network without any recurrent connections
Answer: A
Explanation: GRU is an RNN architecture that combines the forget and input gates of LSTM into a single update gate, making it computationally more efficient while still handling long-term dependencies.
Question 9:
Which RNN variant is best suited for tasks involving very long sequences, like language translation?
A. Vanilla RNN
B. Bidirectional RNN
C. Simple RNN without gates
D. Feedforward Neural Network
Answer: B
Explanation: Bidirectional RNNs process the sequence in both forward and backward directions, allowing them to capture context from both past and future states, which is useful for tasks like translation.
Question 10:
How do RNNs differ from Convolutional Neural Networks (CNNs)?
A. RNNs are better for spatial data, while CNNs handle sequences
B. RNNs process sequential data, whereas CNNs are for grid-like data
C. RNNs use only linear activations, unlike CNNs
D. Both are identical in architecture
Answer: B
Explanation: RNNs are designed for sequential data with temporal dependencies, while CNNs excel at processing data with spatial hierarchies, such as images.
Question 11:
What is a common application of RNNs in natural language processing?
A. Image classification
B. Speech recognition
C. Object detection
D. Anomaly detection in static data
Answer: B
Explanation: RNNs, especially variants like LSTMs, are widely used for speech recognition because they can model the temporal aspects of audio sequences effectively.
Question 12:
During training, what algorithm is typically used for RNNs to handle sequences?
A. Backpropagation
B. Backpropagation through time
C. Gradient descent without updates
D. Forward propagation only
Answer: B
Explanation: Backpropagation through time unfolds the RNN over time and applies standard backpropagation to the unrolled network, accounting for the sequential nature of the data.
Question 13:
What issue can arise when training RNNs on very long sequences?
A. Exploding gradients
B. Overly fast convergence
C. Immediate overfitting
D. Lack of sequential data
Answer: A
Explanation: Exploding gradients occur when gradients become too large during backpropagation through time, causing unstable training; techniques like gradient clipping are used to mitigate this.
Question 14:
In RNNs, what does the term “unrolling” mean?
A. Converting the network into a fully connected layer
B. Expanding the recurrent network into a deep feedforward network for each time step
C. Reducing the number of hidden layers
D. Removing loops from the architecture
Answer: B
Explanation: Unrolling represents the RNN as a series of layers, one for each time step, which simplifies the application of backpropagation through time.
Question 15:
How can RNNs be used in time series forecasting?
A. By treating each data point as independent
B. By predicting future values based on past sequences
C. By ignoring temporal patterns
D. By converting time series to images
Answer: B
Explanation: RNNs analyze historical patterns in time series data through their recurrent connections, enabling predictions of future values based on sequential context.
Question 16:
What is a major advantage of RNNs over traditional neural networks?
A. Ability to handle fixed-size inputs only
B. Capacity to process inputs of variable lengths
C. Faster training times without sequences
D. No need for activation functions
Answer: B
Explanation: Unlike traditional neural networks, RNNs can manage sequences of arbitrary lengths, making them ideal for dynamic data like text or video.
Question 17:
What is a disadvantage of using vanilla RNNs?
A. They are too accurate for most tasks
B. They struggle with very long-term dependencies due to vanishing gradients
C. They require no computational resources
D. They cannot be used for sequential data
Answer: B
Explanation: Vanilla RNNs often fail to learn from information far back in the sequence because gradients diminish over many time steps, leading to poor performance on long sequences.
Question 18:
How do stateful RNNs differ from stateless ones?
A. Stateful RNNs reset the hidden state after each batch
B. Stateless RNNs maintain the hidden state across batches
C. Stateful RNNs preserve the hidden state between batches for continuity
D. Both are identical in operation
Answer: C
Explanation: In stateful RNNs, the hidden state from one batch is carried over to the next, which is useful for processing very long sequences that span multiple batches.
Question 19:
Which technique is used to prevent overfitting in RNNs?
A. Dropout
B. Increasing the learning rate
C. Removing all hidden layers
D. Using only linear activations
Answer: A
Explanation: Dropout randomly drops units during training to prevent co-adaptation of neurons, helping RNNs generalize better to unseen data.
Question 20:
In comparison to LSTMs, what makes GRUs preferable in some scenarios?
A. GRUs have more gates, making them more complex
B. GRUs are faster and require fewer parameters while performing similarly
C. GRUs cannot handle sequences
D. GRUs are only for image data
Answer: B
Explanation: GRUs have fewer parameters than LSTMs due to their simplified gate structure, leading to faster training and lower computational demands, especially for smaller datasets.
or
Part 3: Save time and energy: generate quiz questions with AI technology
Automatically generate questions using AI