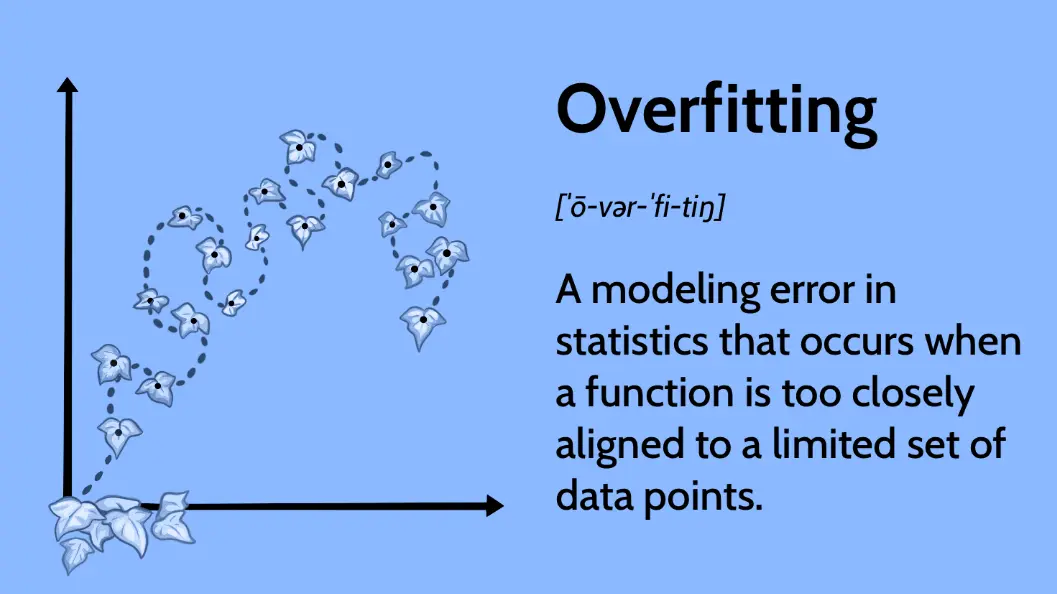
Overfitting in machine learning occurs when a model learns the noise and specific patterns in the training data too well, at the expense of its ability to generalize to new, unseen data. This results in high accuracy on training sets but poor performance on validation or test sets.
Causes
Model Complexity: Models with too many parameters relative to the dataset size can capture irrelevant details.
Insufficient Data: Limited training examples force the model to over-rely on idiosyncrasies.
Noisy Data: Presence of errors or outliers in the training set can mislead the model.
Detection
Error Comparison: Training error is low, but validation error is significantly higher.
Learning Curves: Plotting training and validation errors over epochs shows the training error continuing to decrease while validation error rises.
Cross-Validation: Techniques like k-fold validation reveal inconsistencies in performance across subsets.
By addressing overfitting, models achieve better generalization, leading to more robust and reliable outcomes in practical scenarios.
Table of contents
- Part 1: Create a overfitting quiz in minutes using AI with OnlineExamMaker
- Part 2: 20 overfitting quiz questions & answers
- Part 3: AI Question Generator – Automatically create questions for your next assessment
Part 1: Create a overfitting quiz in minutes using AI with OnlineExamMaker
When it comes to ease of creating a overfitting assessment, OnlineExamMaker is one of the best AI-powered quiz making software for your institutions or businesses. With its AI Question Generator, just upload a document or input keywords about your assessment topic, you can generate high-quality quiz questions on any topic, difficulty level, and format.
Overview of its key assessment-related features:
● AI Question Generator to help you save time in creating quiz questions automatically.
● Share your online exam with audiences on social platforms like Facebook, Twitter, Reddit and more.
● Instantly scores objective questions and subjective answers use rubric-based scoring for consistency.
● Simply copy and insert a few lines of embed codes to display your online exams on your website or WordPress blog.
Automatically generate questions using AI
Part 2: 20 overfitting quiz questions & answers
or
1. Question: What is overfitting in the context of machine learning?
A. When a model performs well on training data but poorly on new data.
B. When a model performs poorly on both training and new data.
C. When a model is too simple and underperforms on training data.
D. When a model achieves perfect accuracy on all data.
Answer: A
Explanation: Overfitting occurs because the model learns the noise and details in the training data to the extent that it negatively impacts the model’s performance on new, unseen data.
2. Question: Which of the following is a common cause of overfitting?
A. Using a model that is too simple for the data.
B. Training with a very large dataset.
C. Using a model with too many parameters relative to the data size.
D. Applying regularization techniques early.
Answer: C
Explanation: A model with too many parameters can capture random fluctuations in the training data, leading to poor generalization on new data.
3. Question: How can cross-validation help prevent overfitting?
A. By increasing the model’s complexity.
B. By evaluating the model on multiple subsets of the data.
C. By reducing the size of the training dataset.
D. By ignoring validation data entirely.
Answer: B
Explanation: Cross-validation assesses the model’s performance on different subsets, helping to identify if the model is overfitting by showing how well it generalizes.
4. Question: In a learning curve, what indicates potential overfitting?
A. Training error decreases while validation error increases.
B. Both training and validation errors decrease equally.
C. Validation error is lower than training error.
D. Training error remains high throughout.
Answer: A
Explanation: If training error keeps decreasing but validation error starts increasing, it suggests the model is fitting the training data too closely and not generalizing.
5. Question: What role does regularization play in addressing overfitting?
A. It adds more features to the model.
B. It penalizes large coefficients in the model.
C. It increases the training data size.
D. It simplifies the model’s architecture.
Answer: B
Explanation: Regularization techniques, like L1 or L2, add a penalty for larger weights, preventing the model from becoming too complex and overfitting.
6. Question: Which technique is NOT typically used to prevent overfitting?
A. Dropout in neural networks.
B. Increasing the learning rate.
C. Early stopping.
D. Data augmentation.
Answer: B
Explanation: Increasing the learning rate can lead to instability and potentially worsen overfitting, whereas the other options directly help in generalization.
7. Question: What is the difference between overfitting and underfitting?
A. Overfitting occurs with too much data; underfitting with too little.
B. Overfitting fits training data well but not new data; underfitting fits neither well.
C. Overfitting is only in complex models; underfitting in simple ones.
D. There is no difference; they are the same.
Answer: B
Explanation: Overfitting means the model is too tailored to training data, while underfitting means it’s too basic to capture patterns in any data.
8. Question: In decision trees, how does pruning help with overfitting?
A. By adding more branches to the tree.
B. By removing unnecessary branches.
C. By increasing the tree’s depth.
D. By ignoring feature importance.
Answer: B
Explanation: Pruning simplifies the decision tree by cutting back branches that do not provide significant improvements, reducing the risk of overfitting.
9. Question: What does a high variance in a model indicate?
A. The model is underfitting.
B. The model is overfitting.
C. The model has low bias.
D. The model performs equally on all datasets.
Answer: B
Explanation: High variance means the model’s performance varies greatly between training and test data, a hallmark of overfitting.
10. Question: Which metric can help detect overfitting during model evaluation?
A. Accuracy on the training set only.
B. The difference between training and validation accuracy.
C. Speed of model training.
D. Number of features used.
Answer: B
Explanation: A large gap between training and validation accuracy suggests overfitting, as the model excels on seen data but not on unseen data.
11. Question: How does ensemble methods like random forests reduce overfitting compared to a single decision tree?
A. By using only one tree.
B. By averaging predictions from multiple trees.
C. By simplifying each tree.
D. By ignoring outliers.
Answer: B
Explanation: Ensemble methods combine multiple models, reducing the impact of overfitting in any single model through averaging or voting.
12. Question: What is early stopping in the context of overfitting?
A. Stopping training when validation error increases.
B. Stopping training after a fixed number of epochs.
C. Increasing the batch size during training.
D. Reducing the model’s parameters mid-training.
Answer: A
Explanation: Early stopping halts training once the model’s performance on validation data begins to worsen, preventing overfitting.
13. Question: In linear regression, what can lead to overfitting?
A. Using too few predictors.
B. Including irrelevant predictors with high multicollinearity.
C. Having a very large sample size.
D. Applying feature scaling.
Answer: B
Explanation: Irrelevant predictors can cause the model to fit noise, leading to overfitting by making the model overly complex.
14. Question: Which of the following best describes the bias-variance tradeoff in relation to overfitting?
A. High bias leads to overfitting.
B. High variance leads to overfitting.
C. Low bias and low variance is ideal.
D. Bias and variance are unrelated.
Answer: B
Explanation: Overfitting is associated with high variance, where the model varies too much with the training data and fails to generalize.
15. Question: How does data augmentation help prevent overfitting in image classification?
A. By reducing the dataset size.
B. By creating more training variations of the data.
C. By simplifying the model architecture.
D. By removing noisy images.
Answer: B
Explanation: Data augmentation generates additional training samples through transformations, helping the model generalize better and avoid overfitting.
16. Question: What is the primary goal of feature selection in avoiding overfitting?
A. To add more features for accuracy.
B. To reduce the number of irrelevant features.
C. To increase model complexity.
D. To ignore correlation between features.
Answer: B
Explanation: Feature selection simplifies the model by keeping only the most relevant features, reducing the chance of overfitting to noise.
17. Question: In neural networks, what does dropout do to combat overfitting?
A. It drops the learning rate.
B. It randomly drops units during training.
C. It increases the number of layers.
D. It stops training abruptly.
Answer: B
Explanation: Dropout prevents co-adaptation of neurons by randomly disabling them during training, making the network more robust and less prone to overfitting.
18. Question: Why might a model overfit when trained on a small dataset?
A. Because small datasets have too much variety.
B. Because the model can memorize the limited data points.
C. Because small datasets always lead to underfitting.
D. Because it requires more parameters.
Answer: B
Explanation: With a small dataset, a complex model can easily memorize the data, including noise, resulting in overfitting.
19. Question: Which visualization technique can help identify overfitting?
A. Confusion matrix.
B. Learning curves.
C. Histogram of features.
D. Scatter plot of predictions.
Answer: B
Explanation: Learning curves plot training and validation errors over time, revealing overfitting when training error is low but validation error is high.
20. Question: What is one way to quantify overfitting in model evaluation?
A. By calculating the model’s speed.
B. By computing the generalization error gap.
C. By checking the number of epochs.
D. By evaluating only on training data.
Answer: B
Explanation: The generalization error gap, such as the difference between training and test error, measures how much the model is overfitting.
or
Part 3: AI Question Generator – Automatically create questions for your next assessment
Automatically generate questions using AI