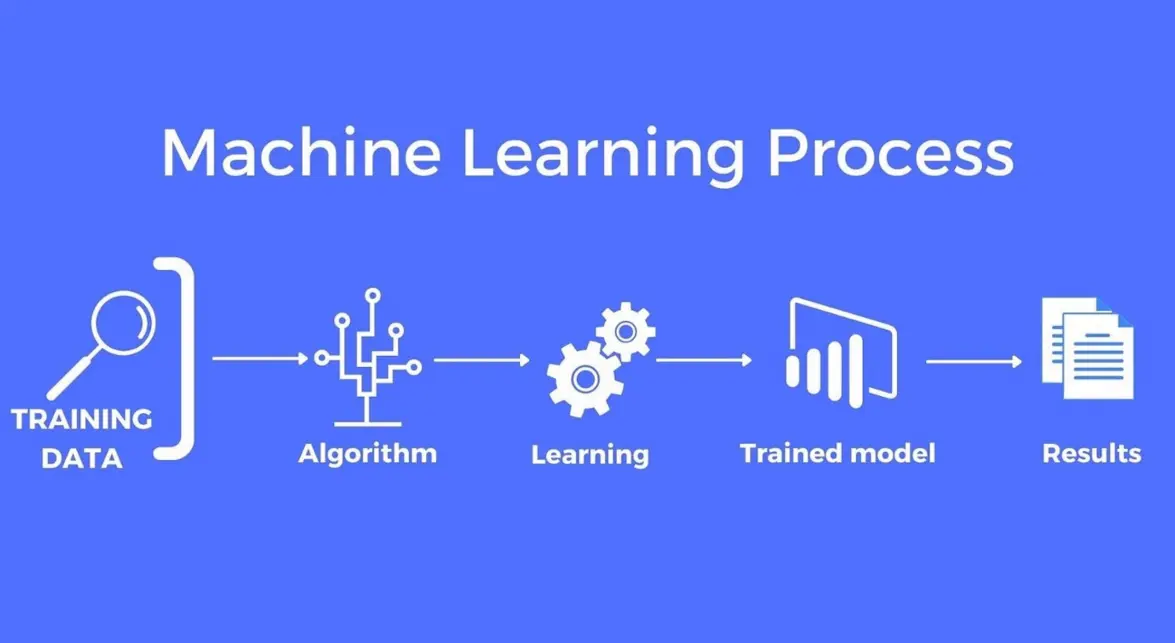
Model training is a critical process in machine learning that involves preparing data, selecting algorithms, and iteratively improving a model’s performance to make accurate predictions or decisions. Below is a step-by-step overview:
1. Data Preparation: Begin by gathering and cleaning data. This includes collecting relevant datasets, handling missing values, removing duplicates, and performing feature engineering to transform raw data into a usable format. Normalization or scaling is often applied to ensure features are on similar scales.
2. Data Splitting: Divide the dataset into subsets: typically, a training set (70-80% of data) for model learning, a validation set for hyperparameter tuning, and a test set for final evaluation. This helps prevent overfitting and ensures unbiased assessment.
3. Model Selection: Choose an appropriate algorithm based on the problem type (e.g., regression, classification, clustering). Common options include linear regression, decision trees, neural networks, or ensemble methods like Random Forest.
4. Training the Model: Feed the training data into the algorithm. The model learns patterns by adjusting internal parameters through optimization techniques, such as gradient descent, to minimize the loss function (e.g., mean squared error for regression).
5. Hyperparameter Tuning: Optimize hyperparameters (e.g., learning rate, number of layers) using methods like grid search or random search on the validation set to enhance model performance.
6. Evaluation: Assess the trained model using metrics such as accuracy, precision, recall, F1-score for classification, or R-squared for regression. Compare results on the test set to gauge generalization.
7. Overfitting and Underfitting Checks: Monitor for overfitting (model performs well on training data but poorly on new data) by using techniques like cross-validation or regularization (e.g., L1/L2 penalties).
8. Deployment and Iteration: Once satisfied, deploy the model for real-world use. Continuously monitor its performance and retrain with new data as needed to maintain accuracy over time.
This process ensures models are robust, efficient, and adaptable to evolving datasets.
Table of contents
- Part 1: Create an amazing model training quiz using AI instantly in OnlineExamMaker
- Part 2: 20 model training quiz questions & answers
- Part 3: Try OnlineExamMaker AI Question Generator to create quiz questions
Part 1: Create an amazing model training quiz using AI instantly in OnlineExamMaker
Nowadays more and more people create model training quizzes using AI technologies, OnlineExamMaker a powerful AI-based quiz making tool that can save you time and efforts. The software makes it simple to design and launch interactive quizzes, assessments, and surveys. With the Question Editor, you can create multiple-choice, open-ended, matching, sequencing and many other types of questions for your tests, exams and inventories. You are allowed to enhance quizzes with multimedia elements like images, audio, and video to make them more interactive and visually appealing.
Recommended features for you:
● Prevent cheating by randomizing questions or changing the order of questions, so learners don’t get the same set of questions each time.
● Automatically generates detailed reports—individual scores, question report, and group performance.
● Simply copy a few lines of codes, and add them to a web page, you can present your online quiz in your website, blog, or landing page.
● Offers question analysis to evaluate question performance and reliability, helping instructors optimize their training plan.
Automatically generate questions using AI
Part 2: 20 model training quiz questions & answers
or
1. Question: What is the primary purpose of training a machine learning model?
A. To test the model on new data
B. To adjust the model’s parameters based on input data
C. To visualize the data
D. To deploy the model in production
Answer: B
Explanation: Training a model involves updating its parameters using algorithms like gradient descent to minimize the loss function and improve predictions based on the training data.
2. Question: In machine learning, what does overfitting indicate?
A. The model performs well on training data but poorly on new data
B. The model performs poorly on both training and new data
C. The model has too few features
D. The model is trained for too few epochs
Answer: A
Explanation: Overfitting occurs when a model learns the noise in the training data, leading to high accuracy on training data but poor generalization to unseen data.
3. Question: Which loss function is commonly used for binary classification problems?
A. Mean Squared Error
B. Cross-Entropy Loss
C. Mean Absolute Error
D. Hinge Loss
Answer: B
Explanation: Cross-Entropy Loss is suitable for binary classification as it measures the difference between the predicted probabilities and the actual labels, helping the model learn to distinguish between two classes.
4. Question: What role does the learning rate play in gradient descent?
A. It determines the batch size
B. It controls how much the model’s parameters are updated in each iteration
C. It sets the number of epochs
D. It defines the activation function
Answer: B
Explanation: The learning rate scales the size of the steps taken during parameter updates in gradient descent; a too-high rate can cause instability, while a too-low rate can slow convergence.
5. Question: Why is data normalization important before training a model?
A. It increases the dataset size
B. It helps gradients flow more effectively and speeds up convergence
C. It adds more features to the data
D. It prevents underfitting
Answer: B
Explanation: Normalization scales features to a similar range, which prevents features with larger scales from dominating the learning process and improves the efficiency of optimization algorithms.
6. Question: What is the difference between batch gradient descent and stochastic gradient descent?
A. Batch uses the entire dataset per update, while stochastic uses one sample
B. Batch is faster, while stochastic is more accurate
C. Batch requires more memory, while stochastic uses less
D. Both are the same
Answer: A
Explanation: Batch gradient descent computes the gradient on the full dataset for each update, making it more stable but slower, whereas stochastic gradient descent updates parameters after each sample, offering faster but noisier convergence.
7. Question: In neural networks, what does an epoch represent?
A. A single training example
B. One forward and backward pass through the entire dataset
C. The learning rate value
D. The number of layers
Answer: B
Explanation: An epoch is a complete iteration over the entire training dataset, allowing the model to learn from all data once before repeating the process.
8. Question: Which technique is used to prevent overfitting in model training?
A. Increasing the model complexity
B. Regularization, such as L1 or L2
C. Using a smaller dataset
D. Decreasing the learning rate
Answer: B
Explanation: Regularization adds a penalty to the loss function for large weights, discouraging overly complex models and improving generalization to new data.
9. Question: What is cross-validation used for in model training?
A. To evaluate the model’s performance on unseen data
B. To train the model faster
C. To select features
D. To visualize the model’s architecture
Answer: A
Explanation: Cross-validation assesses how well a model generalizes by splitting the data into subsets, training on some, and testing on others, reducing the risk of overfitting.
10. Question: Why might a model underfit during training?
A. The model is too complex for the data
B. The model is too simple or the training data is insufficient
C. There is too much regularization
D. The learning rate is too high
Answer: B
Explanation: Underfitting happens when a model is not complex enough to capture the underlying patterns in the data, often due to insufficient features or training time.
11. Question: In supervised learning, what is the role of labels?
A. To define the input features
B. To guide the model in learning the correct outputs
C. To split the data
D. To compute the loss function
Answer: B
Explanation: Labels provide the ground truth outputs that the model uses to compare against its predictions, allowing it to adjust parameters during training.
12. Question: What is the purpose of hyperparameter tuning?
A. To adjust the model’s weights during training
B. To optimize parameters like learning rate and number of layers for better performance
C. To normalize the data
D. To evaluate the model on test data
Answer: B
Explanation: Hyperparameter tuning involves testing different values for settings that are not learned from data, such as learning rate, to find the configuration that yields the best model performance.
13. Question: Which metric is used to measure the performance of a regression model?
A. Accuracy
B. Mean Squared Error
C. Precision
D. F1-Score
Answer: B
Explanation: Mean Squared Error calculates the average squared difference between predicted and actual values, quantifying how well the regression model fits the data.
14. Question: How does increasing the number of epochs affect model training?
A. It always improves accuracy
B. It can lead to overfitting if continued too long
C. It reduces the dataset size
D. It decreases the learning rate
Answer: B
Explanation: More epochs allow the model to learn from the data repeatedly, but excessive epochs can cause the model to memorize noise, resulting in overfitting.
15. Question: What is gradient descent?
A. A method to add more layers to a neural network
B. An optimization algorithm that minimizes the loss function by adjusting parameters
C. A technique for data preprocessing
D. A way to evaluate model accuracy
Answer: B
Explanation: Gradient descent uses the gradient of the loss function to iteratively move towards the minimum loss, thereby optimizing the model’s parameters.
16. Question: In transfer learning, why is a pre-trained model used?
A. To start training from scratch
B. To leverage knowledge from a model trained on a similar task, saving time and resources
C. To increase the dataset size
D. To simplify the architecture
Answer: B
Explanation: Pre-trained models have already learned useful features from large datasets, allowing faster and more efficient training on new, related tasks with limited data.
17. Question: What does the bias-variance tradeoff mean in model training?
A. Balancing the model’s simplicity and its ability to fit data
B. Increasing bias to reduce variance
C. Using biased data for training
D. Minimizing the loss function
Answer: A
Explanation: The tradeoff involves finding a balance where a model is complex enough to capture patterns (low bias) but not so complex that it overfits (high variance).
18. Question: Which type of learning requires labeled data?
A. Unsupervised learning
B. Supervised learning
C. Reinforcement learning
D. Both B and C
Answer: D
Explanation: Supervised learning uses labeled data for training, while reinforcement learning involves labels in the form of rewards, though it’s not purely supervised.
19. Question: How does dropout help in training neural networks?
A. By randomly dropping neurons during training to prevent overfitting
B. By increasing the learning rate
C. By adding more layers
D. By normalizing inputs
Answer: A
Explanation: Dropout randomly deactivates a portion of neurons in each training iteration, forcing the network to learn more robust features and reducing dependency on specific neurons.
20. Question: What is early stopping in model training?
A. Stopping training when the model reaches 100% accuracy
B. Halting training when validation performance stops improving to prevent overfitting
C. Using a smaller batch size
D. Increasing the number of epochs
Answer: B
Explanation: Early stopping monitors validation loss and stops training once it begins to worsen, ensuring the model generalizes well without unnecessary training.
or
Part 3: Try OnlineExamMaker AI Question Generator to create quiz questions
Automatically generate questions using AI